

RAG 的概念解释
RAG架构,以向量检索为核心,已经成为解决大型模型获取最新外部知识和消除生成偏差的主流技术框架,在多个应用场景中得到了广泛应用和验证。
开发者可以利用这一技术以极低的成本构建智能客服、企业智能知识库、AI搜索引擎等应用,实现通过自然语言与各种知识组织形式进行高效对话。例如,一个典型的RAG应用如下:
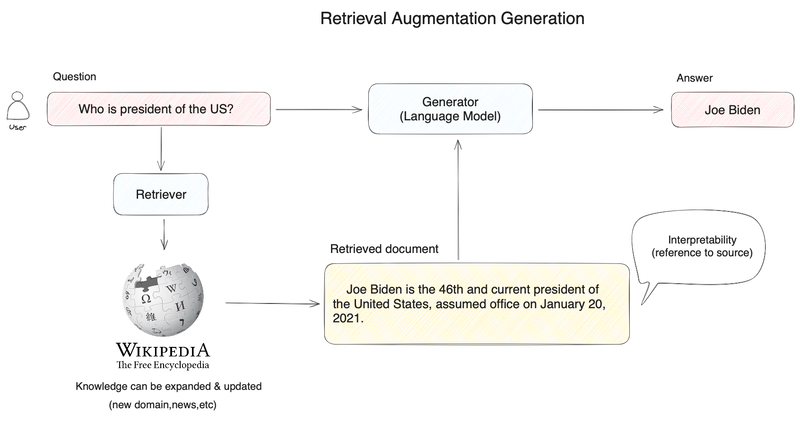
当用户询问“美国总统是谁?”时,系统不直接请求大模型回答,而是首先在知识库(如维基百科)中进行向量搜索,通过语义相似度匹配找到相关的信息(例如,拜登是美国现任第46届总统…)。接着,系统将用户提问和检索到的相关知识一同提供给大模型,确保大模型能够基于充足的知识给出可靠的答案。
为什么需要这样做呢?
大型语言模型可以被视作一个超级专家,他精通各个领域的知识,但也有其局限性。例如,他无法了解个人私密信息,因为这些数据不会公开在互联网上,也没有预先学习这些信息的机会。
如果你考虑雇佣这位超级专家作为家庭财务顾问,你需要允许他查看你的投资和消费记录等数据,这样他才能为你量身定制专业建议。
RAG 系统的核心功能在于帮助大型模型获取其内部未具备的外部知识,使其能够在回答问题之前先行查找答案。
通过以上例子,我们可以清晰地看到,RAG 系统中最关键的步骤是外部知识的检索过程。一个专家是否能够为你提供专业的家庭财务建议,很大程度上取决于他是否能够准确地获取所需的信息。如果他查找到的不是投资理财记录,而是家庭减肥计划,即使是再出色的专家也会无法发挥作用。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
THE END







暂无评论内容