
一、RAG (Retrieval Augmented Generation)
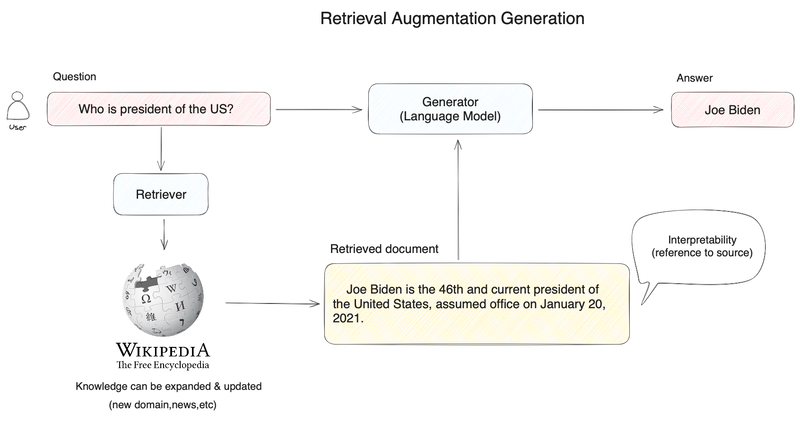
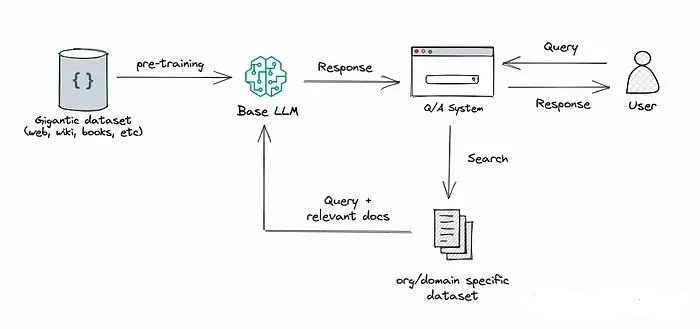
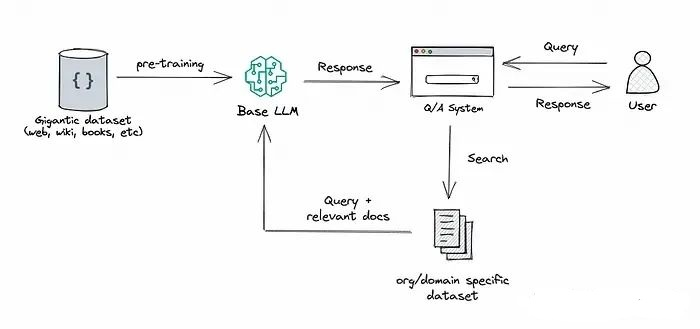
RAG技术结合了检索和生成的方法,通常依赖于两个关键组件:一个大型语言模型(例如GPT-3)和一个检索系统(如向量数据库)。它首先使用检索系统从大量数据中提取相关信息,然后将这些信息传递给语言模型,用于生成回答或文本。这种方法使得RAG能够充分利用语言模型强大的生成能力,并结合检索系统提供的具体信息。
RAG的方法将检索能力集成到大型语言模型中。它整合了一个检索系统和一个大模型,前者从广泛的语料库中检索相关的文档片段,后者利用这些片段中的信息生成答案。总体来说,RAG帮助模型通过“查找”外部信息来改进其输出。
RAG特点
- 知识方面:RAG能够通过快速更新数据库来反映最新信息,而无需重新训练模型,从而快速更新知识库。效果方面:RAG在稳定性和可解释性方面表现良好,因为它生成的回答基于检索到的具体事实。成本方面:在推理过程中,RAG需要额外的检索步骤,这可能增加实时性的成本。
RAG优势
- 更新速度快:仅需更新数据库,无需重新训练模型。
稳定性高:基于事实的检索结果有助于提升答案的精准度。
可解释性强:检索到的信息可作为生成答案的依据,提升了答案的可信度。
RAG劣势
- 搜索的效果直接受到搜索系统质量的影响。搜索过程的实时性提高会增加时间和计算资源成本。
二、微调(Fine-tuning)
微调是指在已经进行过预训练的大型语言模型的基础上,利用特定领域的小型数据集进行进一步训练的过程。这个过程使得模型能够学习和适应特定领域的知识,从而提升在具体任务上的表现能力。
通过微调,我们利用预先训练好的大型语言模型,并在相对较小的特定领域数据集上进行进一步训练,以使模型更贴近特定任务的需求或提高其性能。这种方式可以通过调整模型权重来优化模型,以更好地满足我们应用程序的具体需求。
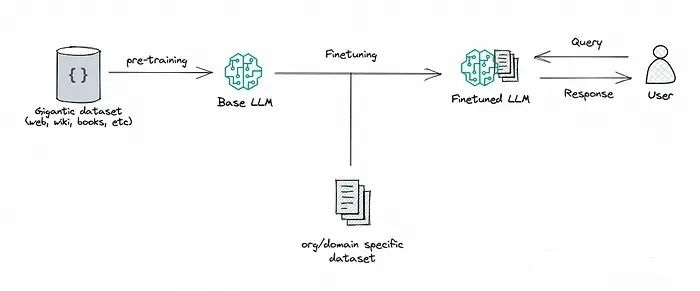
微调特点
- 知识维度:微调通过训练使模型获得新的领域知识,需要相对足量的领域数据。
- 效果维度:对于简单的任务,微调可能达到更高的效果上限,因为它可以针对性地调整模型参数。
- 成本维度:微调需要大量的计算资源(如GPU),且训练时间较长。
微调优势
- 领域适应性:能够学习特定领域的深入知识。
- 性能潜力:对于简单任务,可能达到比RAG更高的性能。
微调劣势
- 资源消耗大:需要大量的计算资源和时间进行训练。
- 知识遗忘:容易遗忘未在训练数据中出现的知识。
三、RAG和微调的适应场景
- 知识更新:RAG通过更新数据库来更新知识,微调则是通过重新训练来吸收新知识。
- 效果稳定性:RAG通常在生成回答时更稳定,而微调可能达到更高的性能上限。
- 资源消耗:微调在训练时消耗资源较多,RAG在推理时增加额外的检索成本。
RAG适用场景
- 知识需要快速更新的领域。
- 对实时性要求不是特别高的应用场景。
- 需要高度可解释性或准确性的场景。
微调适用场景
- 数据量较小但质量高的领域。
- 对模型效果有较高要求,且可以承担相应计算资源消耗的场景。
- 领域知识比较独特,需要模型深入学习的场景。
四、RAG+微调
RAG和微调各自有其独特的优势,在某些情况下,结合它们可以最大化整体效果和效率。以下是一些建议,说明在哪些场景下结合使用RAG和微调是有益的:
### 建议场景:
1. **复杂且知识密集的任务**:
– **使用RAG的优势**:快速检索广泛的背景信息。
– **微调的作用**:深入理解和解释复杂细节,特别是需要领域专业知识的情况。
2. **数据更新频繁的场景**:
– **使用RAG的优势**:快速更新基础知识库。
– **微调的作用**:帮助模型适应新的数据分布和变化。
3. **对实时性要求高的场景**:
– **使用RAG的优势**:快速的检索能力。
– **微调的作用**:优化模型以减少对检索系统的依赖,提高响应速度。
4. **资源受限的场景**:
– **使用RAG的优势**:降低对大量微调数据的依赖。
– **微调的作用**:集中在关键信息或难以检索的内容上,提高效率。
### 结合使用方式:
1. **分阶段训练**:
– **初步使用RAG**:快速获取相关信息。
– **识别不足并微调**:分析并解决RAG在特定任务中的不足,使用微调优化模型。
2. **联合训练**:
– **同时训练检索和生成**:在微调过程中,同时优化检索和生成组件,提升协同效果。
– **使用伪标签**:利用生成模型生成的伪标签来训练检索组件,反之亦然,增强模型整体表现。
3. **迭代优化**:
– **循环迭代**:通过迭代优化闭环,不断提升模型的综合能力和性能。
4. **领域适应**:
– **先微调后RAG**:针对特定领域需求,首先微调模型以适应特定情境,再使用RAG来补充和更新模型的知识。
这种结合使用的方法能够充分发挥RAG在快速检索方面的优势,同时利用微调在深度理解和个性化适应方面的能力,从而提升模型在复杂任务中的整体表现。同时,这种策略也有助于平衡实时性、准确性和资源消耗等多方面的需求。
五、基于微调+RAG的项目案例:特定主题的问答系统
下面是简化的项目案例,我们将展示如何利用RAG和微调技术来构建一个太空探索主题的问答系统:
1. **数据集准备**
– 收集关于“太空探索”主题的问题和答案数据集。
– 将数据集分成训练集和验证集。
2. **RAG检索组件配置**
– 使用向量数据库存储与“太空探索”主题相关的文档。
– 配置检索系统,使其能够从数据库中检索与输入问题相关的文档。
3. **初步微调**
– 对大型语言模型进行初步微调,以使其能够更好地理解和回答“太空探索”主题的问题。
4. **RAG与微调的结合**
– 结合使用RAG和微调后的语言模型来构建问答系统。
– 当系统收到问题时,首先使用RAG检索相关文档,然后使用微调后的模型从这些文档中生成准确和适合上下文的答案。
这个项目案例展示了如何通过利用RAG来快速获取相关信息,并通过微调来提高语言模型的回答准确性和适应性,从而创建一个高效的太空探索主题问答系统。
# 导入必要的库
from transformers import GPT2LMHeadModel, GPT2Tokenizer
from retriever import VectorDBRetriever # 假设的检索器库
import torch
# 初始化模型和分词器
model = GPT2LMHeadModel.from_pretrained('gpt2')
tokenizer = GPT2Tokenizer.from_pretrained('gpt2')
# 初始化向量数据库检索器
retriever = VectorDBRetriever('space_exploration') # 假设的数据库
# 微调模型
def fine_tune(model, tokenizer, train_dataset):
# 微调代码省略,通常包括数据加载、模型训练等步骤
# RAG流程
def rag_process(question):
# 检索相关信息
relevant_docs = retriever.retrieve(question)
# 使用检索到的文档生成回答
context = ' '.join(relevant_docs)
input_ids = tokenizer.encode(f'{question}{context}', return_tensors='pt')
output = model.generate(input_ids, max_length=100, num_return_sequences=1)
answer = tokenizer.decode(output[0], skip_special_tokens=True)
return answer
# 微调后的RAG流程
def fine_tuned_rag_process(question):
# 微调模型
fine_tune(model, tokenizer, train_dataset)
# 使用微调后的模型进行RAG流程
return rag_process(question)
# 示例问题
question = "What is the Hubble Space Telescope?"
answer = fine_tuned_rag_process(question)
print(answer)
请注意,上述代码片段是伪代码,仅用于说明概念。实际的实现将涉及详细的模型微调流程、数据预处理以及集成向量数据库等复杂步骤。
数据准备:确保数据集的质量和覆盖范围,这对微调的效果至关重要。
微调策略:选择合适的微调策略,如学习率、批次大小和训练周期等。
检索组件:建立高效的检索系统,能够快速准确地找到相关文档。
通过结合使用RAG和微调,我们能够构建一个同时具备广泛知识背景和深度学习特定领域能力的问答系统。